
Java应用程序诊断、调试工具
引言
在 Java 开发的广袤领域中,性能与故障问题如同隐藏在暗处的礁石,时刻考验着开发者的技术功底与应变能力。当应用程序在高并发的浪潮中运行时,可能会出现响应迟缓、内存溢出等状况,而在日常运维中,也可能遭遇线程死锁、JVM 参数配置不合理等棘手难题。这些问题不仅影响应用的稳定性和用户体验,严重时甚至会导致业务中断,带来不可估量的损失。
此时,JDK 自带的工具就如同开发者手中的利刃,能够精准地剖析问题的本质。它们是 JDK 精心打造的 “瑞士军刀”,涵盖了线程分析、内存诊断、性能监控等多个维度,为开发者提供了深入洞察 Java 应用程序内部运行机制的能力。通过这些工具,开发者可以深入到 JVM 的底层,查看线程的执行堆栈、分析内存的使用情况、监控垃圾回收的过程,从而快速定位问题根源,制定出有效的解决方案。
jstack:线程分析利器
工具简介
jstack 是 JDK 自带的一款线程分析工具,其全称为 Java Stack Trace。它的核心功能是生成 Java 虚拟机的线程快照,这个快照中详细记录了 JVM 中所有线程在某一时刻的状态,如线程是处于运行(RUNNABLE)、阻塞(BLOCKED)、等待(WAITING)还是计时等待(TIMED_WAITING)等状态 ,同时还包含了线程的调用栈信息,即当前执行的方法链。通过分析这些信息,开发者能够深入了解线程的执行情况和相互之间的关系。
在使用 jstack 时,其基本命令格式为jstack [options] <pid>,其中<pid>指的是目标 Java 进程的进程 ID。在 Windows 系统中,我们可以借助任务管理器或 tasklist 命令来获取 Java 进程的 ID;而在 Linux 或 Unix 系统中,则可使用 ps 命令来完成这一操作。例如,在 Linux 系统中,若要查看进程 ID 为 12345 的 Java 进程的线程堆栈信息,只需在命令行中输入jstack 12345即可。此外,jstack 还提供了一些可选参数,如-l用于显示更多关于锁的信息,这在诊断死锁等与锁相关的问题时非常有用;-F则用于当目标进程不响应时强制打印堆栈信息 ,不过使用该参数时需格外小心,因为它可能会对目标进程产生影响。
常用命令
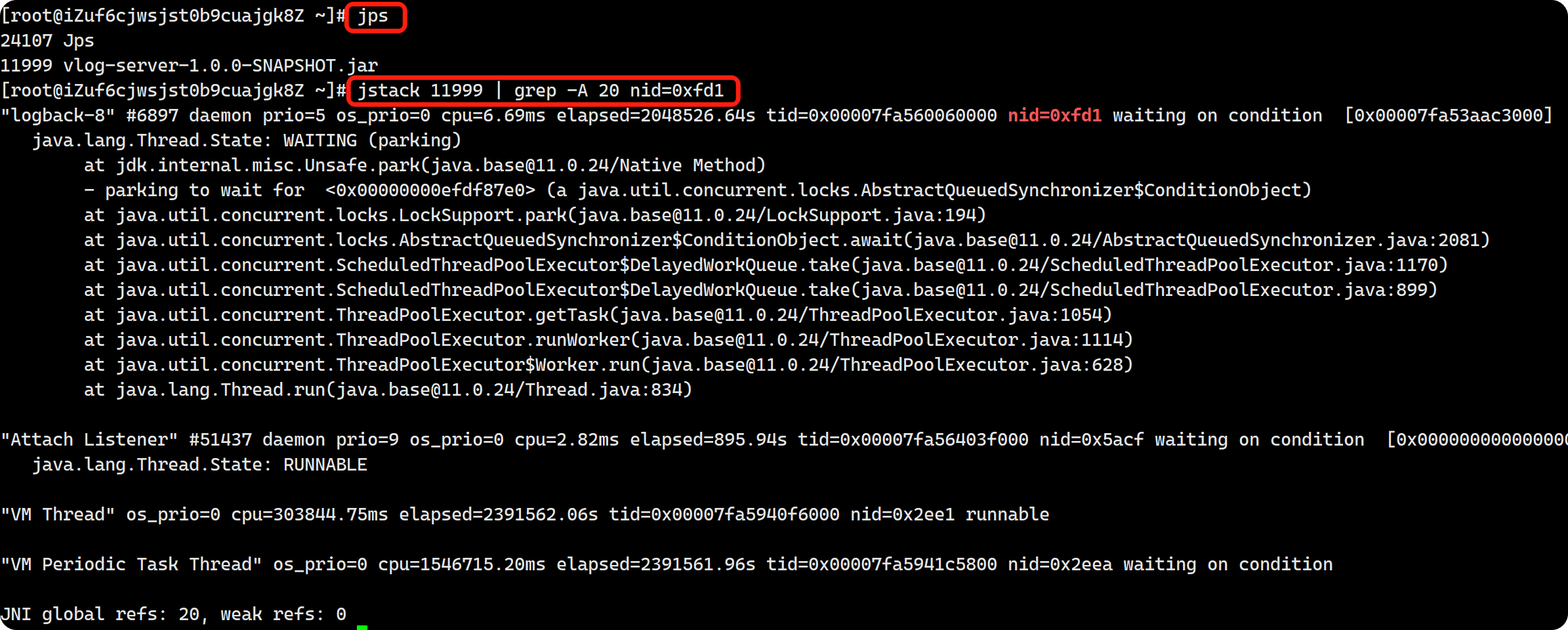
jps 查出当前java进程id为 11999:
jstack 11999控制台打印线程快照jstack -l 11999显示锁的附加信息,在基本堆栈信息基础上,额外输出线程持有的锁信息(如synchronized锁的所有者、等待队列等),诊断死锁(死锁时会明确标记 "Found one Java-level deadlock")、分析锁竞争问题。jstack -F 11999强制输出快照 ,当正常命令(无-F)无法响应时(如进程挂起),强制生成线程快照(通过操作系统信号强制获取),强制模式下输出的信息可能不如正常模式完整。jstack 11999 > ./thread.dump.txt线程快照信息输出到文件中jstack 11999 | grep -A 20 deadlock结合grep过滤特定线程jstack 11999 | grep "tid" | wc -l过滤后统计行数,这里是统计线程数量
使用场景
死锁排查:死锁是多线程编程中较为常见且棘手的问题,它会导致程序无法正常运行,线程相互等待对方释放资源,形成僵持局面。当怀疑程序出现死锁时,jstack 便成为了我们排查问题的有力工具。通过jstack -l <pid>命令生成线程快照,在输出结果中搜索 “deadlock” 关键字,若存在死锁,jstack 会清晰地标注出死锁相关的线程信息,包括哪些线程在等待哪些资源,以及这些资源被哪些线程持有,从而帮助开发者快速定位死锁根源。
CPU 占用过高分析:当 Java 应用程序出现 CPU 占用率异常飙升的情况时,可能是某个线程中的代码存在性能问题,如死循环、复杂的计算逻辑等。此时,我们可以先用 top 命令定位到占用 CPU 高的进程 PID,再通过top -Hp pid命令查找该进程下最耗 CPU 的线程 ID ,将线程 ID 转换为 16 进制格式后,使用jstack pid | grep tid -A 60命令打印线程的堆栈信息。通过分析堆栈信息中处于 RUNNABLE 状态的线程的调用栈,能够找出占用 CPU 过高的代码片段,进而进行针对性的优化。
线程池状态检查:在使用线程池的 Java 应用中,有时会出现任务执行速度变慢、线程池队列积压等问题。借助 jstack,我们可以查看线程池中的线程状态和调用栈。例如,通过查找线程池中线程的名称或特定的标识,分析线程是否处于等待任务(WAITING)、获取任务(RUNNABLE)等状态,以及线程在执行任务过程中是否存在阻塞或异常情况,以此来判断线程池的运行状况,优化线程池的配置和任务调度策略。
实际案例
比如我们在测试过程中,发现程序偶尔会出现无响应的情况,经过初步判断,怀疑是出现了死锁。
死锁代码示例:
package com.vvhz.jvm;
public class DeadLockTest {
private static Object lock1 = new Object();
private static Object lock2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
synchronized (lock1) {
try {
System.out.println("thread1 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock2) {
System.out.println("thread1 end");
}
}
}).start();
new Thread(() -> {
synchronized (lock2) {
try {
System.out.println("thread2 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock1) {
System.out.println("thread2 end");
}
}
}).start();
System.out.println("main thread end");
}
}首先,使用jps命令获取目标 Java 进程的 ID,假设获取到的进程 ID 为 8056。然后执行jstack -l 8056 > thread_dump.txt命令,将线程快照输出到thread_dump.txt文件中。
打开thread_dump.txt文件,搜索 “deadlock” 关键字,或者直接执行jstack -l 8056 | grep "deadlock" -A 20检索,发现如下信息:
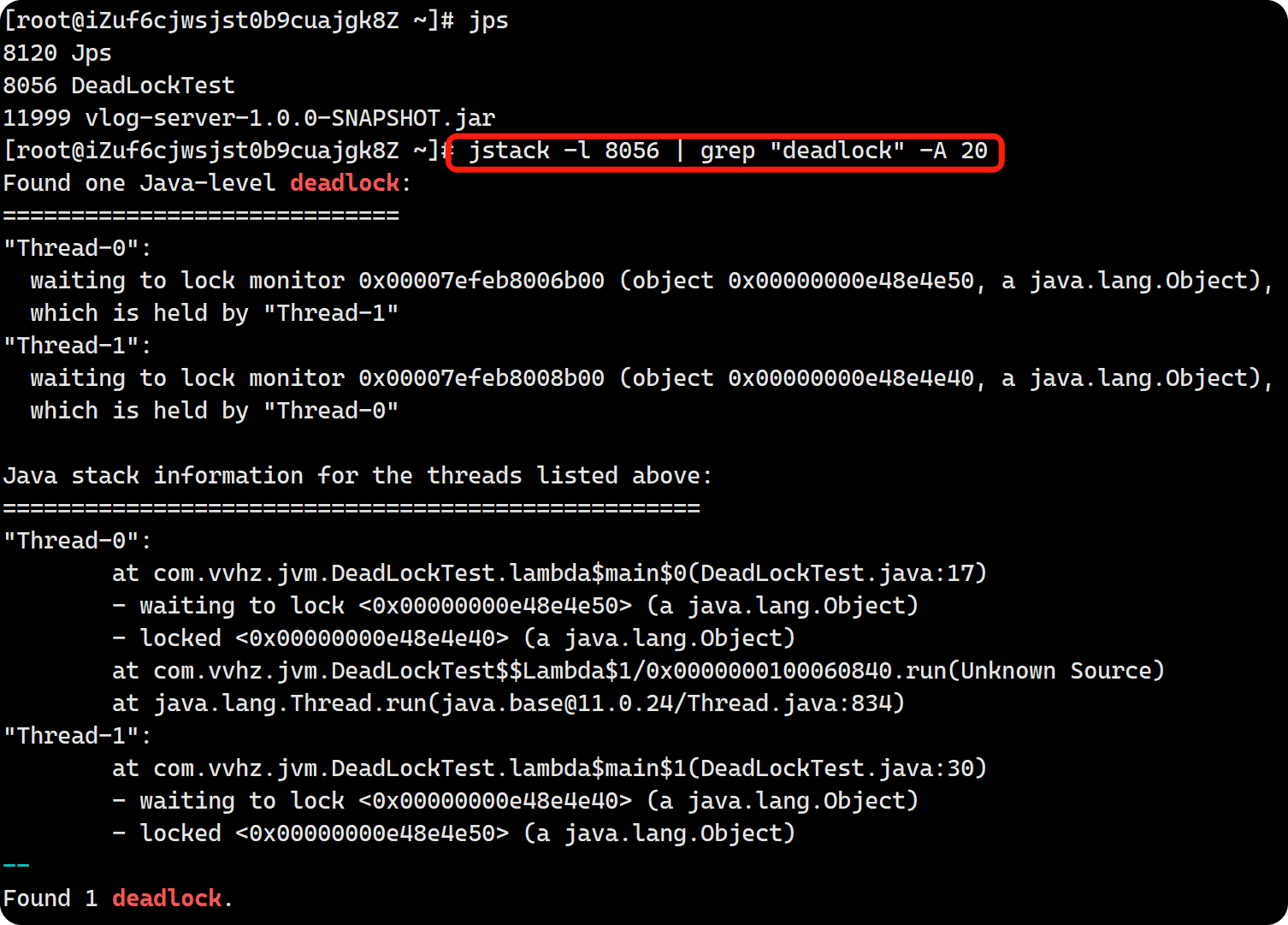
从上述信息可以看出,Thread-0 和 Thread-1 发生了死锁,Thread-0 等待 Thread-1 释放0x00000000e48e4e50对象的锁,而 Thread-1 等待 Thread-0 释放0x00000000e48e4e40对象的锁。
进一步查看这两个线程的调用栈信息,
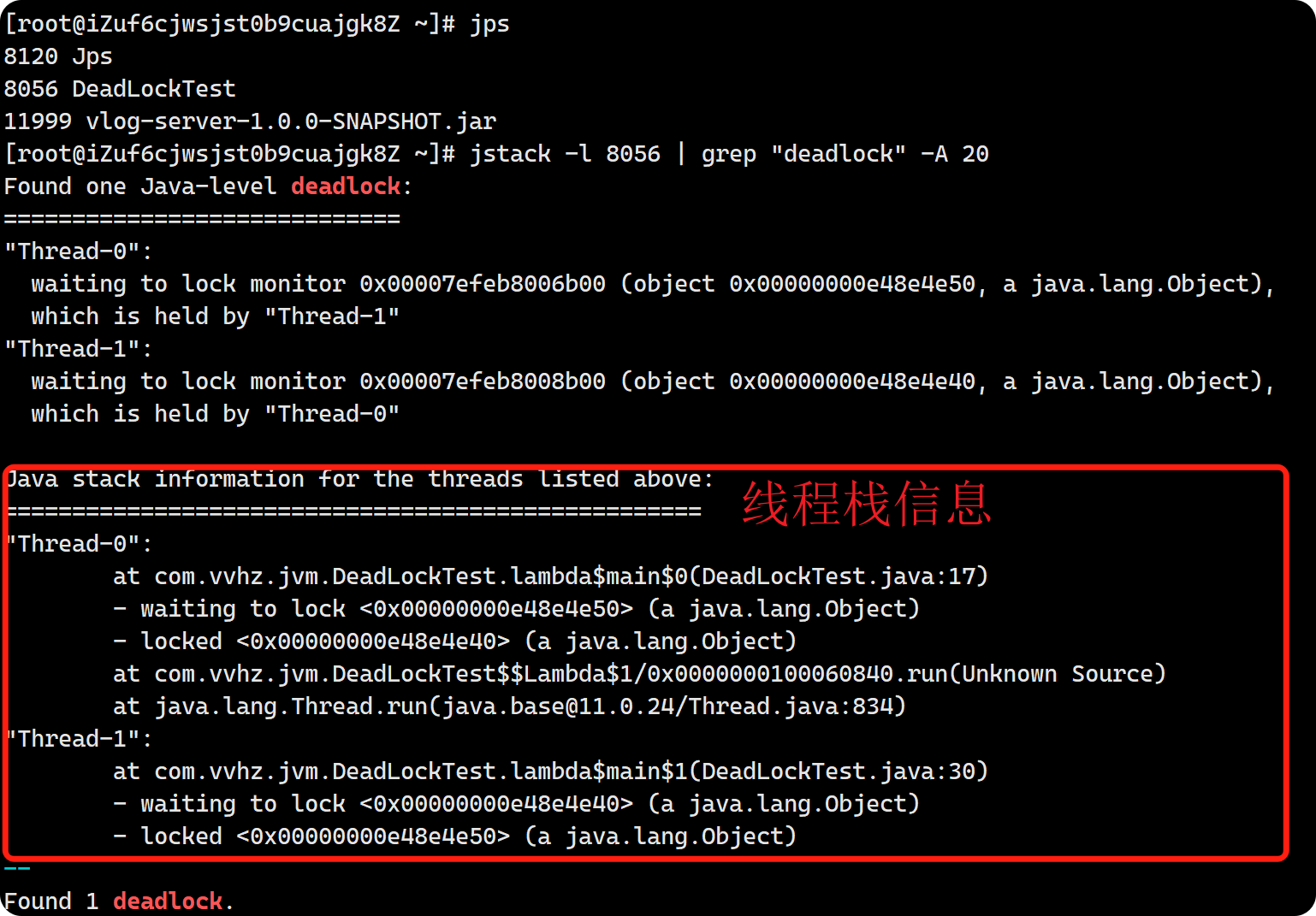
通过分析调用栈,发现问题出在DeadLockTest类中的第17行。通过这些信息,我们就可以确定我们代码出现死锁的位置,然后修改对应的代码即可。
jmap:内存分析神器
工具简介
jmap(Java Memory Map)是 JDK 提供的一款强大的内存分析工具,主要用于生成 Java 堆转储快照(heap dump),也被称为 heapdump 或 dump 文件。这个快照是 Java 堆内存的一个瞬时镜像,包含了堆中所有对象的详细信息,如对象的类型、数量、大小以及对象之间的引用关系等 。通过分析这些信息,开发者能够深入了解 Java 应用程序的内存使用情况。
在命令行中使用 jmap 时,其基本语法为jmap [option] <pid>,其中<pid>表示目标 Java 进程的 ID。jmap 提供了丰富的选项来满足不同的分析需求,例如-heap选项用于打印 Java 堆的概要信息,包括使用的垃圾回收算法、堆配置参数以及各代堆内存的使用情况等;-histo[:live]选项可以打印 Java 堆中对象的直方图,展示每个类的对象数目、占用内存大小和类全名信息,如果加上:live,则只统计存活对象 ;-dump:format=b,file=filename选项用于以 HPROF 二进制格式将 Java 堆信息输出到指定文件,该文件可使用专业的内存分析工具如 Eclipse MAT(Memory Analyzer Tool)、JProfiler 等进行深入分析。
使用场景
内存泄漏排查:内存泄漏是指程序中已分配的内存由于某种原因无法被释放或回收,导致内存占用不断增加,最终可能引发应用程序崩溃。当怀疑应用程序存在内存泄漏时,可使用 jmap 生成堆转储文件。通过分析堆转储文件中对象的存活情况和引用关系,能够找出那些本应被回收但仍被持有引用的对象,从而定位内存泄漏的根源。例如,在一个长时间运行的 Web 应用中,如果发现内存使用持续上升,使用jmap -dump:format=b,file=heap_dump.hprof <pid>命令生成堆转储文件,再利用 Eclipse MAT 分析文件,查找出占用大量内存且未被正常回收的对象,进一步分析这些对象的引用链,判断是否存在内存泄漏。
对象分布和内存使用分析:在性能优化过程中,了解应用程序中对象的分布情况和内存占用情况非常重要。使用jmap -histo <pid>命令可以获取每个类的对象数量和内存占用大小,通过对这些数据的分析,能够找出占用内存较大的对象类型和数量较多的对象,从而有针对性地进行优化。比如在一个大数据处理应用中,通过分析jmap -histo的输出结果,发现某个自定义的数据结构对象占用了大量内存,进一步检查代码,发现该数据结构在某些情况下创建了过多不必要的实例,通过优化代码减少了该对象的创建数量,从而降低了内存占用。
垃圾回收行为调优:jmap 的-heap选项可以提供关于垃圾回收的详细信息,如当前使用的垃圾回收算法、堆内存的配置参数以及各代堆内存的使用情况等。这些信息有助于开发者了解垃圾回收的运行状态,判断垃圾回收是否正常工作,是否需要调整堆内存大小或垃圾回收器参数。例如,通过jmap -heap <pid>命令查看堆内存的使用情况,如果发现老年代内存增长过快且频繁触发 Full GC,可能需要调整新生代和老年代的比例,或者更换更适合的垃圾回收器。
常用命令
jps 查出当前java进程id为 12300:
jmap -heap 12300查看堆内存整体信息jmap -histo 12300按照类名统计对象数量和内存占用。jmap -histo 12300 | sort -k 2 -nr | head -n 10按照实例数倒序排序jmap -dump:format=b,file=heap_dump.hprof 12300生成二进制格式的堆快照(最常用)。诊断内存泄漏(通过分析对象引用链找到未释放的对象)、分析大对象分布等。生成快照时可能导致进程短暂暂停(尤其堆较大时),建议在非高峰期执行。jmap -dump:live,format=b,file=live_heap_dump.hprof 12300只dump存活对象(需配合GC,可能影响性能)jmap -clsstas 12300输出各加载器加载的类数量、占用内存,以及加载器自身信息。分析类加载器泄漏(如自定义类加载器未被回收导致大量类信息堆积)。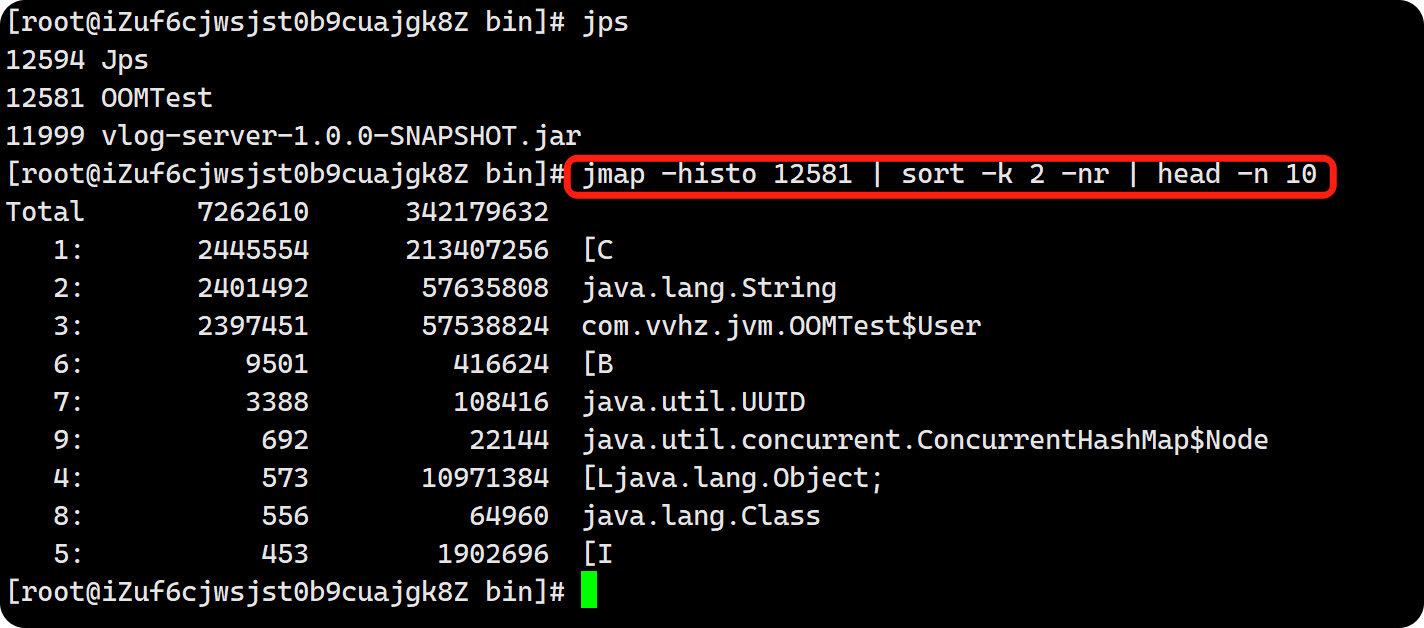
实际案例
假设我们的系统,在运行一段时间后,发现内存占用持续上升,怀疑存在内存泄漏问题。
示例代码:
package com.vvhz.jvm;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
public class OOMTest {
public static List<Object> list = new ArrayList<>();
// JVM设置
// ‐Xms10M ‐Xmx10M ‐XX:+PrintGCDetails ‐XX:+HeapDumpOnOutOfMemoryError ‐XX:HeapDumpPath=D:\jvm.dump
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
int i = 0;
int j = 0;
while (true) {
list.add(new User(i++, UUID.randomUUID().toString()));
new User(j--, UUID.randomUUID().toString());
}
}
public static class User {
private int i;
private String s;
public User(int i, String s) {
this.i = i;
this.s = s;
}
}
}首先,使用jps命令获取目标 Java 进程的 ID,假设获取到的进程 ID 为 12345。然后执行jmap -dump:format=b,file=heap_dump.hprof 12345命令,生成堆转储文件heap_dump.hprof。
然后,我们可以使用 JVisualVM 工具打开heap_dump.hprof文件。分析哪个对象的实例数量异常。
jstat:性能监控大师
工具简介
jstat(Java Virtual Machine Statistics Monitoring Tool)是用于监视虚拟机各种运行状态信息的命令行工具,主要利用 JVM 内建的指令对 Java 应用程序的资源和性能进行实时监控,包括了对 Heap size 和垃圾回收状况的监控。它可以显示本地或远程虚拟机进程中的类加载、内存、垃圾收集、即时编译器等运行时数据 ,对于服务器端应用程序的性能分析和调优非常有用,特别是在没有 GUI 界面的服务器环境中。
jstat 命令的基本格式为jstat [option] <vmid> [interval [s|ms] [count]]。其中,option是用于指定不同监控选项的参数,决定了显示的信息类型;<vmid>是 Java 虚拟机的进程 ID,如果是本地虚拟机进程,VMID 就是 LVMID(本地虚拟机进程 ID),对于远程虚拟机进程,VMID 的格式更为复杂,需包含协议、主机名、端口等信息 ;interval表示查询间隔时间,单位可以是毫秒(ms)或秒(s),若省略则只查询一次;count代表查询次数,若省略则会一直查询。例如,jstat -gc 12345 1000 5表示每隔 1000 毫秒查询一次进程 ID 为 12345 的 Java 虚拟机的垃圾回收情况,共查询 5 次。
使用场景
监控各代堆内存使用情况:通过jstat -gc <vmid>命令,可以获取各代堆内存的详细使用信息,包括新生代中 Survivor 区(S0C、S1C、S0U、S1U)、Eden 区(EC、EU),老年代(OC、OU)以及元数据区(MC、MU)等的容量和已用空间 。这些信息有助于开发者了解堆内存的分配和使用状况,判断是否存在内存分配不合理的情况。比如,若发现 Eden 区频繁填满且触发 Young GC,可能需要调整新生代的大小;若老年代内存增长过快,可能需要关注对象晋升到老年代的机制以及老年代的回收效率。
垃圾回收统计信息监控:jstat -gcutil <vmid>命令用于监控垃圾回收的统计信息,它以百分比的形式展示各代堆内存的使用情况,同时还包含 Young GC(YGC、YGCT)、Full GC(FGC、FGCT)的次数和时间以及总 GC 时间(GCT) 。通过这些信息,开发者可以评估垃圾回收器的性能,判断垃圾回收是否正常进行。例如,若 YGC 次数频繁且 YGCT 时间较长,可能需要调整新生代的大小或优化新生代的垃圾回收算法;若 FGC 次数过多且 FGCT 时间长,可能需要检查老年代的内存使用情况,是否存在大对象长期占用内存或内存泄漏等问题。
类加载情况监控:使用jstat -class <vmid>命令能够查看类加载的相关统计信息,如已加载的类数量(Loaded)、已加载类的字节总数(Bytes)、已卸载的类数量(Unloaded)、已卸载类的字节总数(Bytes)以及加载类所耗费的时间(Time) 。在应用程序启动和运行过程中,监控类加载情况可以帮助开发者了解应用程序的资源消耗情况。如果发现已加载的类数量异常增多,可能是代码中存在不必要的类加载操作,或者某些类被重复加载,这可能会导致内存占用增加和性能下降,通过分析类加载信息,可以找出问题所在并进行优化。
常用命令
jps 查出当前java进程id为 11999:
jstat -gc 11999查看各代内存使用量及GC次数/时间jstat -gcnew 11999详细展示年轻代GC情况(包括Eden区和Survivor区),主要关注:年轻代内存分配(Eden、Survivor)、Minor GC 次数(YGCT)和耗时,判断年轻代大小是否合理。jstat -gcold 11999详细展示老年代GC情况,主要关注:老年代容量(OC)、使用率(OU)、Full GC 次数(FGC)和耗时(FGCT),判断是否存在老年代内存泄漏(如OU持续增长)。jstat -gc/-gcnew/-gcold 11999 2000 10间隔2000毫秒查询一次,一共查询10次jstat -class 11999查看类加载总数、已加载、未加载数量及耗时。Loaded:已加载的类数量,Bytes:已加载类的总大小(字节),Unloaded:已卸载的类数量,Bytes:已卸载类的总大小,Time:类加载和卸载的总耗时jstat -compiler 11999查看JIT编译器编译的方法数量、耗时等
实际案例
为了更直观地展示 jstat 在监控 Java 应用程序性能方面的作用,我们来看一个具体的案例。假设有如下一段 Java 代码:
public class JstatExample {
public static void main(String[] args) {
byte[] data = new byte[1024 * 1024 * 10]; // 占用10MB内存
try {
Thread.sleep(60000); // 线程睡眠60秒,便于观察
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}这段代码创建了一个大小为 10MB 的字节数组,然后让主线程睡眠 60 秒。
首先,使用jps命令获取该 Java 程序的进程 ID,假设获取到的进程 ID 为 12345。
然后,执行jstat -gc 11999 2000命令,每隔 2 秒查询一次该进程的垃圾回收和堆内存使用情况。输出结果可能如下:
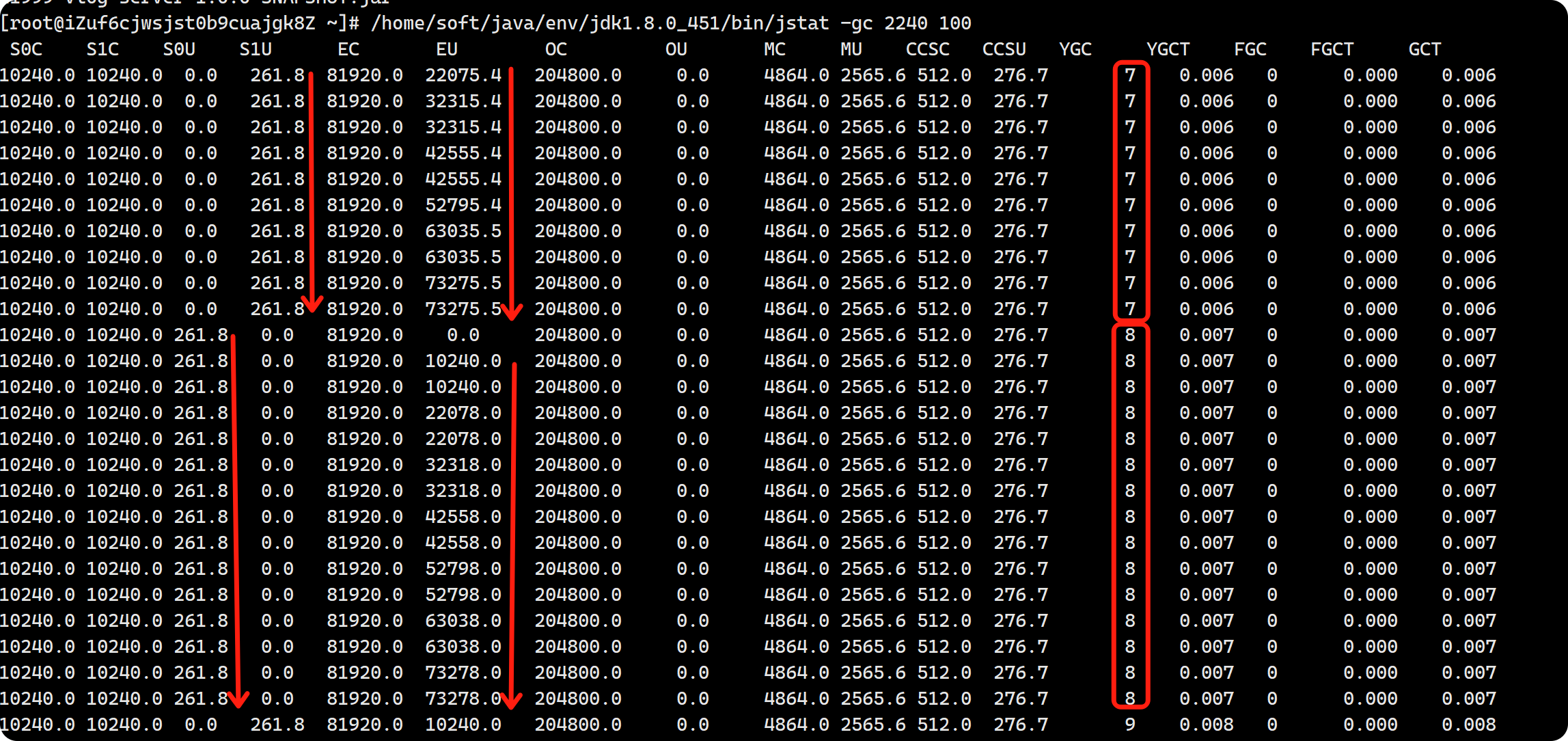
从输出结果中可以看到,随着时间的推移,Eden 区的使用量(EU)逐渐增加,这是因为程序中创建的 10MB 字节数组占用了堆内存。如果 Eden 区的使用量接近或超过其容量(EC),就可能会触发 Young GC,此时 YGC 的次数会增加,YGCT 时间也可能会相应变化。
接着,执行jstat -gcutil 12345 2000命令,查看垃圾回收的百分比统计信息。输出结果可能如下:
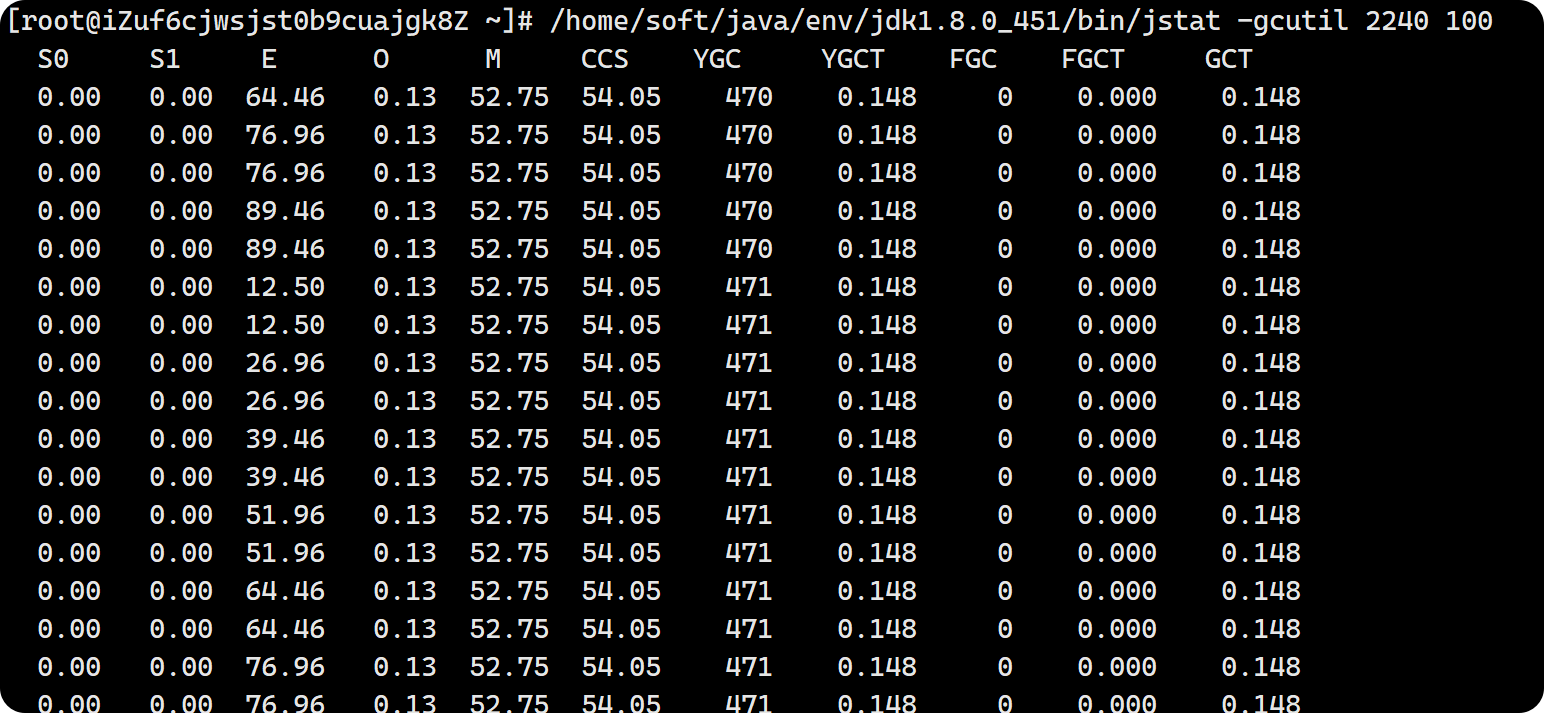
通过这些百分比数据,可以更直观地了解各代堆内存的使用比例以及垃圾回收的情况。例如,E 列表示 Eden 区的使用比例,随着程序的运行,Eden 区的使用比例逐渐上升,当达到一定阈值时,就会触发垃圾回收。
通过这个案例可以看出,jstat 能够实时地监控 Java 应用程序的堆内存使用和垃圾回收情况,为开发者提供了丰富的性能数据,帮助开发者及时发现和解决性能问题,优化应用程序的性能。
jinfo:JVM 配置侦探
工具简介
jinfo(Configuration Info for Java)是 JDK 自带的一款用于查看和修改 Java 虚拟机配置参数的工具。它就像是 JVM 的 “听诊器”,能够深入到 JVM 的内部,获取关于系统属性和 JVM 命令行标志的详细信息 ,为开发者提供了一种在运行时动态调整 JVM 配置的方式。
在命令行中使用 jinfo 时,其基本语法为jinfo [option] <pid>,其中<pid>是目标 Java 进程的进程 ID。option则是一系列可选参数,不同的参数对应不同的功能。例如,-flag <name>用于打印指定 JVM 标志参数的值,如jinfo -flag MaxHeapSize <pid>可以查看目标进程的最大堆内存大小;-flag [+|-]<name>用于启用或禁用指定的 JVM 标志参数,+表示启用,-表示禁用,比如jinfo -flag +PrintGCDetails <pid>可开启详细的垃圾回收日志打印 ;-flags用于打印 JVM 的所有标志参数及其值;-sysprops用于打印 Java 系统属性,如jinfo -sysprops <pid>可以查看目标进程的系统属性,包括 Java 版本、操作系统信息、用户目录等 。
使用场景
查看 JVM 配置参数:在开发和运维过程中,了解 JVM 的当前配置参数至关重要。有时候,开发人员可能不确定某个 JVM 参数的默认值或当前运行时的值,使用 jinfo 可以轻松获取这些信息。例如,通过jinfo -flag SurvivorRatio <pid>可以查看新生代中 Eden 区域与 Survivor 区域的容量比值,帮助开发者判断堆内存的分配是否合理。在排查性能问题时,查看-XX:MaxGCPauseMillis等垃圾回收相关参数的值,能够了解垃圾回收的停顿时间设置,评估垃圾回收器的性能是否满足应用需求。
修改 JVM 配置参数:虽然不是所有的 JVM 参数都支持动态修改,但对于那些被标记为 “manageable” 的参数,jinfo 提供了在运行时修改的能力。这在一些紧急情况下非常有用,比如在应用程序运行过程中,发现垃圾回收过于频繁,影响了系统性能,通过jinfo -flag +PrintGCDetails <pid>开启详细的垃圾回收日志打印,获取更多垃圾回收信息,再根据日志分析结果,使用jinfo -flag MaxGCPauseMillis=500 <pid>动态调整最大垃圾回收停顿时间,尝试优化垃圾回收性能 。不过需要注意的是,动态修改的参数值仅在当前进程运行期间有效,进程重启后会恢复到原来的设置。
诊断环境差异问题:在不同的环境(如开发、测试、生产)中,JVM 的配置可能会有所不同。当应用程序在不同环境中出现不一致的行为时,使用 jinfo 查看各个环境中 JVM 的配置参数,对比差异,有助于找出问题的根源。例如,应用程序在测试环境中运行正常,但在生产环境中出现内存不足的错误,通过jinfo -flags <pid>分别查看测试环境和生产环境中 Java 进程的 JVM 参数,可能会发现生产环境中堆内存的初始值或最大值设置过小,从而进行针对性的调整。
常用命令
jinfo -sysprops 11999输出目标进程的所有系统属性(即System.getProperties()返回的键值对),包括操作系统信息、Java 环境配置、用户自定义属性等。确认系统属性配置(如编码格式file.encoding、工作目录user.dir等)是否符合预期。jinfo -flags 11999输出目标进程的所有 JVM 启动参数,包括显式设置的参数(如-Xms512m)和默认参数(如 JVM 自动分配的堆大小)。验证 JVM 参数是否按预期生效(如确认是否启用了 G1 收集器-XX:+UseG1GC,堆大小是否正确设置等)。jinfo -flag MaxHeapSize 11999查看单个参数的值(如最大堆大小)。jinfo -flag UseGCLogFileRotation 11999查看开关类参数的状态(如是否启用GC日志)。jinfo -flag +PrintGCDetails 11999启用开关型参数(如开启GC详细日志)。jinfo -flag NewRatio=2 11999修改数值型参数(如设置新生代与老年代比例为2)。
实际案例
假设我们正在维护一个在线交易系统,该系统基于 Java 开发并部署在 Linux 服务器上。近期,系统在高并发场景下出现响应迟缓的情况,经过初步排查,怀疑是垃圾回收性能问题。
首先,使用jps命令获取交易系统 Java 进程的 ID,假设获取到的进程 ID 为 12345。
然后,执行jinfo -flag UseG1GC 12345命令,查看当前是否使用 G1 垃圾回收器。如果输出结果为-XX:+UseG1GC,说明当前使用的是 G1 垃圾回收器;若为-XX:-UseG1GC,则表示未使用。
接着,为了获取更详细的垃圾回收信息,执行jinfo -flag +PrintGCDetails 12345命令,开启详细的垃圾回收日志打印。之后,再次进行高并发测试,查看系统日志中垃圾回收的相关信息。
从日志中发现,垃圾回收的停顿时间较长,且频繁触发 Full GC。进一步分析,决定尝试调整 G1 垃圾回收器的最大停顿时间参数。执行jinfo -flag MaxGCPauseMillis=200 12345命令,将最大停顿时间设置为 200 毫秒。
调整参数后,再次进行高并发测试,观察系统的响应情况。通过jstat -gcutil 12345 1000命令监控垃圾回收的统计信息,发现 Full GC 的次数明显减少,系统的响应速度也得到了显著提升,说明通过 jinfo 调整 JVM 参数对解决性能问题起到了积极的作用。
通过这个案例可以看出,jinfo 在诊断和解决 JVM 配置相关问题方面具有重要的作用,能够帮助开发者快速定位问题并采取有效的解决方案,确保 Java 应用程序的稳定高效运行。
总结
在 Java 开发与运维的领域中,jstack、jmap、jstat 和 jinfo 这些 JDK 自带的工具各自闪耀着独特的光芒,成为开发者应对各种性能与配置问题的得力助手。
jstack 如同一位敏锐的侦探,专注于线程世界,能够精准地捕捉到线程的运行状态和堆栈信息,在排查死锁、分析 CPU 占用过高以及检查线程池状态等场景中发挥着关键作用,帮助开发者深入线程内部,解决线程相关的疑难杂症。
jmap 则是内存分析的大师,通过生成堆转储快照,为开发者揭示内存中对象的奥秘,无论是排查内存泄漏,还是分析对象分布和内存使用情况,亦或是调优垃圾回收行为,jmap 都能提供详尽而关键的信息,成为守护 Java 应用内存健康的坚实壁垒。
jstat 作为性能监控的专家,利用 JVM 内建指令对应用程序的资源和性能进行实时监控,从各代堆内存使用情况到垃圾回收统计信息,再到类加载情况,jstat 都能提供全面而细致的数据,为开发者优化应用性能提供了有力的数据支持。
jinfo 则是 JVM 配置的贴心管家,能够查看和修改 JVM 的配置参数,在查看 JVM 配置、修改参数以及诊断环境差异问题等方面发挥着不可或缺的作用,帮助开发者根据应用的实际需求,灵活调整 JVM 的配置,确保应用程序的稳定高效运行。
这些工具并非孤立存在,在实际工作中,它们相互配合,形成了一个强大的工具链。当 Java 应用程序出现性能问题或配置异常时,开发者可以首先使用 jps 定位目标 Java 进程,然后根据具体问题,灵活运用 jstack 分析线程问题,jmap 排查内存故障,jconsole 进行可视化监控,jstat 获取性能数据,jinfo 调整 JVM 配置,从而快速、准确地解决问题。希望开发者们能够熟练掌握并灵活运用这些工具,在 Java 开发与运维的道路上乘风破浪,打造出更加稳定、高效的 Java 应用程序。
{kind=link}
{kind=link}